News
Teaching a Computer to See - A Feature on Dr. Helge Rhodin

Reading this article and looking at its images may seem like a very simple act, but it’s actually a part of a very complex process: sight. It starts with nothing more than light hitting our eyes, but then information is extracted, our brain processes, and finally we can “see”. It’s a process that seems so simple, one that we don’t even think about, but it is actually incredibly intricate. We never learned how to see, like we learned how to walk or talk, but just found ourselves doing it. This prompts the question, if we never learned how to see, how can we teach a computer how to process visual signals like we do?
Most machine learning uses massive amounts of data with manually defined markers in order to allow a learning process to occur. This supervised learning, however, isn’t learning in the same way that we know the word. In order to make machine learning as human as possible, as self-supervised as possible, it needs to resemble the same process as a child learning to see, or so Dr. Helge Rhodin believes. Right now, artificial intelligence is far from exemplary, and it can’t get much better until a machine is able to learn in the same way that living things can.
Dr. Helge Rhodin is an Assistant Professor in Computer Science at the University of British Columbia, and he is a member of CAIDA (the UBC ICICS Centre for Artificial Intelligence Decision-making and Action). His research interests range from computer vision for computer graphics to motion capture with applications in neuroscience.

Dr. Rhodin is interested in the human-centered approach to computer vision and graphics. By creating a bridge of understanding between humans and computers, his work will better be able to connect people with computers in ways that can aid their daily lives.
Dr. Rhodin’s work in computer vision and computer graphics aims to further develop fundamentals that can be applied to other research. In this way, his work becomes very practical and can reach a much larger domain: sometimes even providing other researchers with the tools to achieve things they thought were impossible. Some of his recent work on inferring the motion and behaviour of fruit flies, for example, has allowed neuroscientists the ability to analyse their data more completely, giving them a better understanding of the brain and thereby providing them with the opportunity for innovation in their own research.
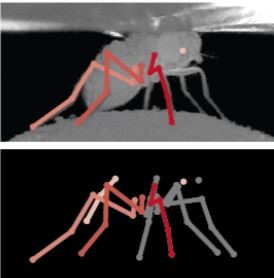
With all of his previous, current, and future research, he’s thought of how it can help people and add to the betterment of our future world. For example, he is currently working on how to use computer vision algorithms to preserve our privacy, without hindering their use in our daily lives. We’ve all heard stories about devices having more information on an individual than was intended, yet we all love the benefits that smart devices have had on our lives. Dr. Rhodin is working on ways to make the technology interlaced with our lives less intrusive while maintaining their function.

Rhodin is perhaps best known for his work with marker-less motion capture, in particular for the developments leading to EgoCap: a new way of using a head-mounted camera to map the basic skeletal structure of an individual in order to capture their movement, without a restricted or complicated set-up. Integrated in VR (Virtual Reality) and AR (Augmented Reality) devices, his vision algorithms can turn 2D-video input into a dynamic 3D scene reconstruction, usable for driving a virtual character and telepresence. His work received the Best Journal Paper Honorable Mention Award at IEEE VR 2019 and has led to increased motion-capture ability for sports, gaming, and even drone flight. Rhodin started to work in this area in 2014 by proposing differentiable computer graphics models, but it is still prevalent today and has extended globally. Recent work on advancing EgoCap includes well-known virtual reality researcher Henry Fuchs who has created his own version which extends to facial capture abilities. Also worth highlighting is a lab team in University College London (UCL) who has worked in collaboration with Facebook and Occulus on furthering egocentric 3D body pose estimation, highlighting the interest in bringing this technology to market. Dr. Rhodin is already known as a pioneer of this sub-field, but the continued work by such high-level groups really shows the impact that his work has had and the distance that this technology can go.
Despite his academic success and bright future, Dr. Rhodin finds the most satisfaction in sharing his passion for science with the up-and-coming students that he’s mentoring. Getting to see them excited, watch their development, and help them to become contributors in the field is the biggest stand-out to Rhodin’s academic career; a fact that is no surprise after talking to him and realizing that Rhodin cares far more about helping people and creating a better world than carving his name into the history books. He may be young in this field, but just the act of getting to do science still puts a light in his eye: now let’s see if he can make a computer see the world in a similar way.
To learn more about Dr. Rhodin's work, check out his website.
Dr. Rhodin's publications that were referenced in this article:
Neuroscience work:
Deformation-aware Unpaired Image Translation for Pose Estimation on Laboratory Animals
Siyuan Li, Semih Günel, Mirela Ostrek, Pavan Ramdya, Pascal Fua, and Helge Rhodin
CVPR 2020
DeepFly3D, a deep learning-based approach for 3D limb and appendage tracking in tethered, adult Drosophila
Semih Günel, Helge Rhodin, Daniel Morales, João H Campagnolo, Pavan Ramdya, Pascal Fua
eLIFE 2019
The EgoCap work:
Mo2Cap2: Real-time Mobile 3D Motion Capture with a Cap-Mounted Fisheye Camera
Weipeng Xu, Avishek Chatterjee, Michael Zollhöfer, Helge Rhodin, Pascal Fua, Hans-Peter Seidel, and Christian Theobalt
TVCG 2019 (IEEE VR) Best Journal Paper Honorable Mention Award
[paper pdf] [video and project page]
EgoCap: Egocentric Marker-less Motion Capture with Two Fisheye Cameras
Helge Rhodin, Christian Richardt, Dan Casas, Eldar Insafutdinov, Mohammad Shafiei, Hans-Peter Seidel, Bernt Schiele, and Christian Theobalt
SIGGRAPH Asia 2016 (oral presentation)
The preparation for EgoCap:
A Versatile Scene Model with Differentiable Visibility Applied to Generative Pose Estimation
Helge Rhodin, Nadia Robertini, Christian Richardt, Hans-Peter Seidel, and Christian Theobalt
ICCV 2015